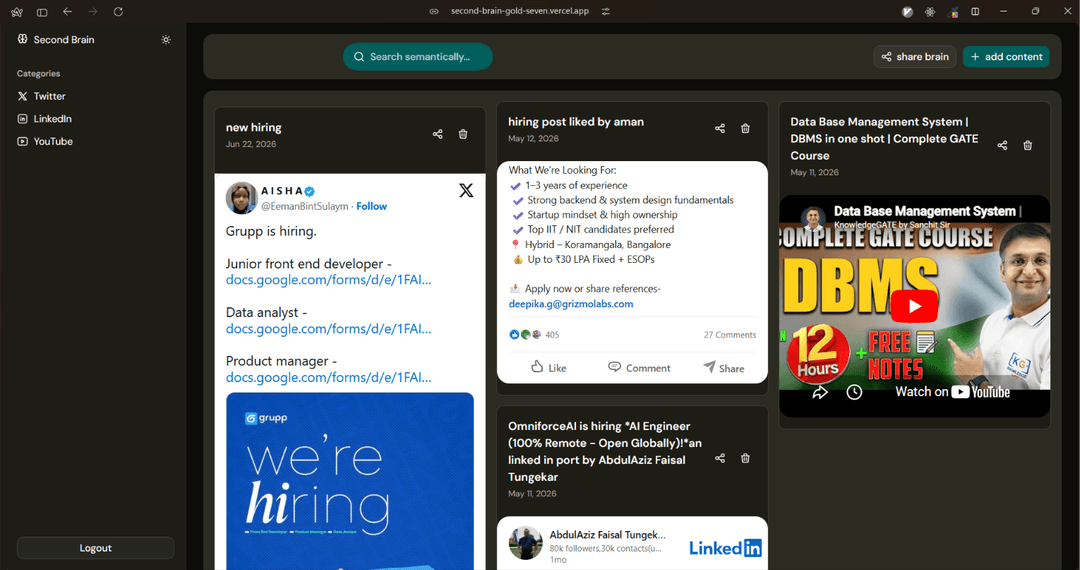
Overview
Second Brain is an AI-powered personal knowledge management platform that allows users to save and organize content from multiple sources such as YouTube videos, Twitter/X posts, LinkedIn posts, articles, and websites.
Instead of relying on traditional keyword-based search, the platform uses vector embeddings and semantic search to help users find information using natural language queries and contextual meaning.
The goal is to create a digital memory system where users can effortlessly store knowledge and retrieve it later, even when they don't remember exact titles, tags, or keywords.
Motivation
People consume large amounts of content every day but often struggle to find it later.
Traditional bookmarking systems have several limitations:
- Depend heavily on exact keywords
- Require manual organization
- Become difficult to navigate over time
- Lack contextual understanding
Second Brain was built to solve these problems by combining structured content storage with AI-powered retrieval.
The platform enables users to:
- Save content from multiple platforms
- Organize knowledge in one place
- Search using concepts instead of exact keywords
- Build a long-term searchable knowledge repository
Core Features
Content Collection
Users can save:
- YouTube videos
- Twitter/X posts
- LinkedIn posts
- Articles
- Blog posts
- Website links
Each saved item is automatically processed and stored with metadata.
Semantic Search
The platform supports natural language search such as:
- "Post about React performance optimization"
- "Video discussing system design interviews"
- "LinkedIn article on startup growth strategies"
Instead of matching exact text, the system understands the meaning behind the query and retrieves the most relevant content.
Collections & Organization
Users can organize content into:
- Collections
- Categories
- Custom groups
- Personal knowledge hubs
This allows both structured organization and AI-assisted discovery.
AI-Powered Retrieval
When a user searches:
- The query is converted into an embedding vector
- Stored content embeddings are searched
- Similar content is ranked by semantic relevance
- The most meaningful results are returned
This enables discovery even when users only remember fragments of information.
High-Level Architecture
Content Ingestion Flow
- User submits a link
- Platform extracts metadata
- Content is cleaned and normalized
- Embeddings are generated
- Content and vectors are stored
- Item becomes available for semantic search
Search Flow
- User enters a search query
- Query is converted into embeddings
- Vector similarity search is performed
- Relevant content is retrieved
- Results are ranked and displayed
Semantic Search Implementation
The most important feature of the platform is its semantic search system.
Traditional search:
- Matches keywords
- Requires exact terms
- Misses related concepts
Semantic search:
- Understands context
- Understands meaning
- Finds conceptually related content
- Improves discovery accuracy
Examples: Query: > "Database optimization"
Can successfully retrieve content discussing:
- Indexing strategies
- Query performance
- PostgreSQL tuning
- Database scaling
Even when the phrase "database optimization" does not appear directly in the saved content.
Embedding Pipeline
Each content item undergoes an embedding generation process.
Processing Steps
- Extract meaningful text
- Remove noise and unnecessary metadata
- Normalize content
- Generate embeddings using AI models
- Store vectors in the database
The generated embeddings act as a numerical representation of meaning, enabling contextual search capabilities.
Authentication & User Management
The platform supports secure user authentication. Features include:
- User accounts
- Protected content storage
- User-specific knowledge bases
- Secure session management
Each user maintains an isolated second brain and can only access their own content.
Database Design
The application uses a relational database structure to manage knowledge efficiently. Key entities include:
- User: Stores account information and ownership of content.
- Content: Stores Title, URL, Type, Metadata, and Content information.
- Collections: Used for organizing saved resources.
- Embeddings: Stores vector representations used for semantic retrieval.
Performance Considerations
To maintain fast search performance:
- Embeddings are generated once during ingestion
- Vector similarity operations are optimized
- Metadata is indexed for filtering
- Content processing occurs before storage
This keeps retrieval fast even as the knowledge base grows.
Security & Privacy
Second Brain follows a privacy-first approach:
- User data remains isolated
- Authentication is required for access
- No public exposure of saved content
- Secure API interactions
- Protected database access
Users retain full control over their knowledge repository.
Technical Challenges
Semantic Search Accuracy
One challenge was ensuring searches remained relevant even when users entered vague or incomplete queries. This was solved through:
- High-quality embeddings
- Proper content preprocessing
- Similarity-based ranking
Content Normalization
Different platforms provide content in different formats. To ensure consistency:
- Metadata extraction was standardized
- Content was normalized before storage
- Searchable context was generated uniformly
Scalable Architecture
The platform was designed to support:
- Thousands of saved links
- Large knowledge repositories
- Fast semantic retrieval
- Future AI-powered features
Tech Stack
Frontend
- Next.js
- React
- TypeScript
- Tailwind CSS
- shadcn/ui
Backend
- Next.js Server Actions
- API Routes
Database
- PostgreSQL
- Prisma ORM
AI & Search
- Mistral Embeddings API
- Vector Embeddings
- Semantic Search
Authentication
- NextAuth.js
Deployment
- Vercel
- PostgreSQL Cloud Database
Future Improvements
Planned features include:
- AI-generated summaries
- Automatic tagging
- Knowledge graph visualization
- Cross-content relationships
- Chat with your Second Brain
- AI-assisted note generation
- Browser extension for one-click saving
Impact
Second Brain transforms passive content consumption into an organized and searchable knowledge system.
Instead of losing valuable information across bookmarks, tabs, and social platforms, users can build a centralized repository that becomes smarter over time through AI-powered semantic search.
The project demonstrates practical applications of:
- Retrieval systems
- Vector embeddings
- Semantic search
- AI-assisted knowledge management
- Modern full-stack development